






MAI-Voice-1: Innovación en Síntesis de Voz con Inteligencia Artificial
En la vanguardia de la inteligencia artificial aplicada a las interfaces de usuario se encuentra MAI-Voice-1, un innovador modelo interno de generación de voz desarrollado por Microsoft. Este recurso representa un avance significativo dentro del marco tecnológico de transformación digital, al ofrecer voces sintéticas con una calidad y expresividad que emulan de manera sorprendente la comunicación humana natural. A diferencia de los sistemas tradicionales de texto a voz que Microsoft ha perfeccionado durante años, MAI-Voice-1 promete no solo mejorar la claridad y naturalidad del habla generada, sino también incorporar matices emocionales y tonos que permiten una interacción más humana y personalizada.
Arquitectura técnica y avances de MAI-Voice-1
Este artículo se sumerge en los detalles técnicos, aplicaciones potenciales y beneficios que ofrece este modelo, aportando a la comprensión profunda de cómo los sistemas de inteligencia artificial están alcanzando niveles más sofisticados en generación de audio, y qué implicaciones tiene esto para el futuro de la comunicación digital.
La síntesis de voz, en el panorama tecnológico actual, ha trascendido las barreras previamente inamovibles, ampliando el espectro de posibilidades en la interacción hombre-máquina. En este contexto, Microsoft ha desempeñado un papel crucial con el desarrollo de MAI-Voice-1, un modelo interno de generación de voz revolucionario que marca un antes y un después en la calidad y naturalidad del audio generado. Este avance se debe, en gran medida, a un enfoque innovador en la arquitectura técnica y la integración de la inteligencia artificial (IA) en el proceso de síntesis de voz.
MAI-Voice-1 representa una evolución significativa respecto a las tecnologías de síntesis de voz anteriores. Tradicionalmente, los sistemas se basaban en la concatenación de sonidos almacenados o en la síntesis formante, que, aunque funcionales, a menudo resultaban en una salida de voz robótica e inerte. En contraste, MAI-Voice-1 emplea técnicas avanzadas de aprendizaje profundo para modelar con precisión las peculiaridades y nuances de la voz humana, resultando en producciones de audio notablemente más naturales y expresivas.
Redes neuronales y aprendizaje profundo
Uno de los pilares de esta revolución es el uso de redes neuronales generativas, específicamente, modelos de transformadores, que permiten una mejor comprensión y reproducción del lenguaje hablado. Al alimentar estos modelos con vastas cantidades de datos de voz, MAI-Voice-1 aprende a imitar las inflexiones, tonos, y variaciones dinámicas de la voz humana de manera excepcionalmente precisa. Este enfoque no solo mejora la calidad del audio generado, sino que también permite una personalización profunda de las voces, pudiendo ajustarse para reflejar diferentes edades, géneros, y acentos con una fidelidad sin precedentes.
Para profundizar más en cómo funcionan las redes neuronales aplicadas a la síntesis de voz, puedes consultar este artículo que describe los sintetizadores de voz, explicando los fundamentos detrás de los sistemas modernos de generación de audio.
Expresión emocional y naturalidad
Además, la incorporación de IA en MAI-Voice-1 facilita la interpretación y expresión de emociones en la síntesis de voz, un aspecto crítico para lograr una comunicación verdaderamente naturalista. A través de técnicas de aprendizaje supervisado y no supervisado, el modelo es capaz de detectar sutilezas en el texto escrito, como la intención y el contexto emocional, y traducirlos en expresiones vocales auténticas. Esta capacidad eleva la experiencia de usuario a un nuevo nivel, permitiendo interacciones más ricas y humanizadas entre máquinas y personas.
Aplicaciones y beneficios de MAI-Voice-1
La importancia de estos avances en la tecnología de generación de voz va más allá de la mera mejora del audio; representa un salto cualitativo en la manera en que interactuamos con las máquinas. Al ofrecer una salida de voz indistinguible de la humana, MAI-Voice-1 se erige como un componente esencial en el futuro de la tecnología asistiva, los sistemas de respuesta de voz interactiva, y las interfaces de usuario basadas en voz, prometiendo una era de interacción hombre-máquina más natural, intuitiva y accesible.
Desde asistentes digitales hasta herramientas de accesibilidad y creación de contenido multimedia, MAI-Voice-1 ofrece una calidad sonora, fidelidad emocional y diversidad vocal que abren un amplio abanico de posibilidades para desarrolladores e investigadores en inteligencia artificial.
¿ Quieres DESTACAR este recurso, herramienta o plataforma sobre Inteligencia Artificial? ¿ Te gustaría estar presente en nuestro directorio ? HAZ CLICK AQUÍ
Conclusiones
MAI-Voice-1 de Microsoft representa un salto cualitativo en la generación de voz artificial gracias a su enfoque interno y la integración de tecnologías avanzadas de inteligencia artificial. Su capacidad para generar voces con una expresividad y naturalidad superior lo posiciona como una herramienta valiosa para una amplia gama de aplicaciones, desde asistentes digitales hasta accesibilidad y creación de contenido multimedia. Recomendamos su evaluación en entornos donde la interacción vocal sea crítica, especialmente en proyectos que requieran voces personalizadas y emocionalmente ricas.
Técnicamente, la arquitectura detrás de MAI-Voice-1 sugiere un modelo optimizado para manejar variaciones tonales y expresivas, permitiendo una respuesta dinámica que mejora la experiencia del usuario final. Para desarrolladores e investigadores en IA, este modelo abre posibilidades para seguir explorando mejoras en la síntesis de voz y potenciar interfaces conversacionales más naturales y efectivas. En definitiva, MAI-Voice-1 es un recurso estratégico dentro del ecosistema de Microsoft que impulsa la frontera de la inteligencia artificial aplicada a la voz, facilitando una integración más fluida y humana en el uso diario de tecnologías conversacionales.
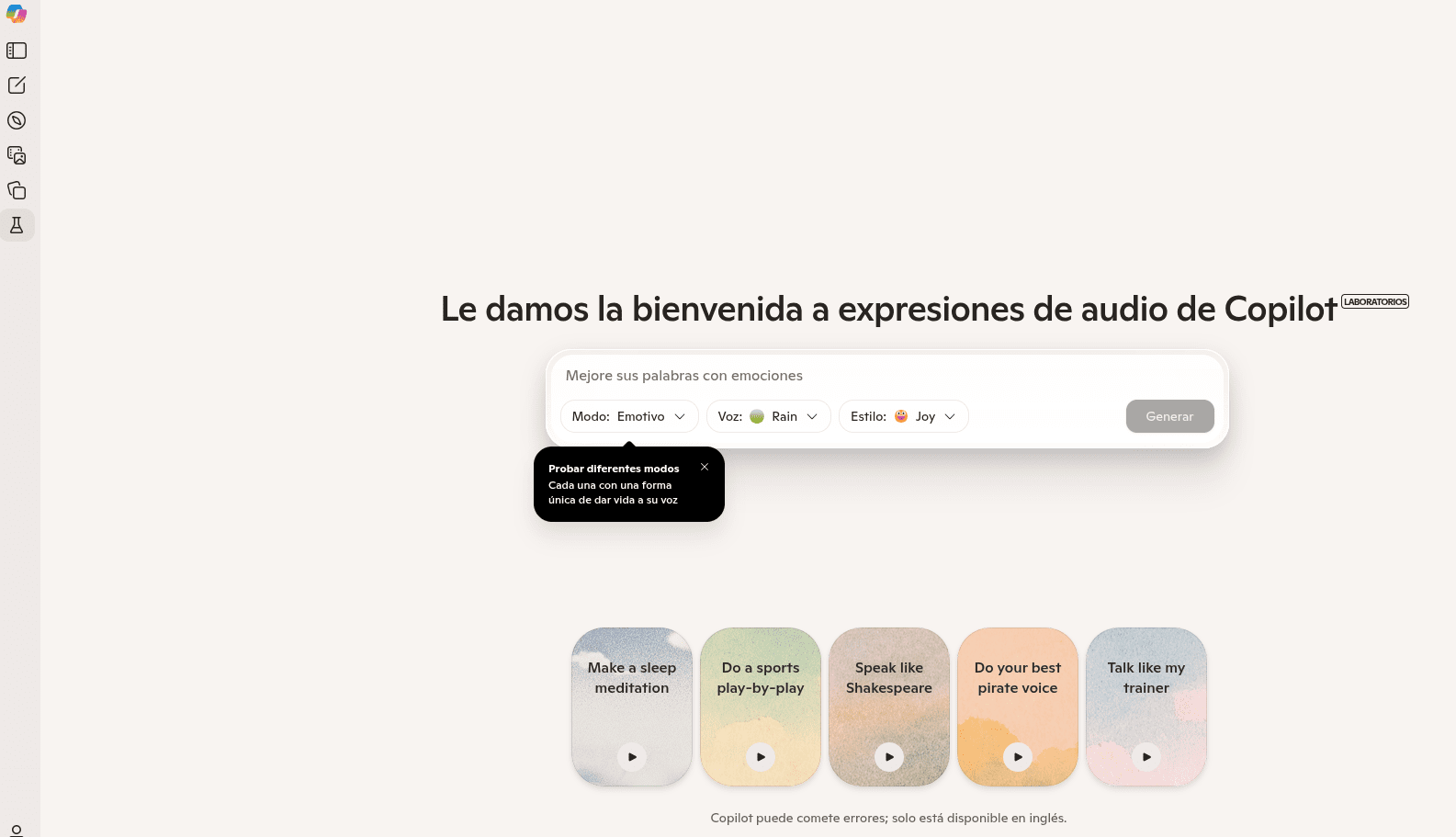
– Web Oficial de MAI-Voice-1 = https://copilot.microsoft.com/labs/audio-expression.
2 respuestas
¡Vaya, MAI-Voice-1 de Microsoft realmente suena a un avance impresionante en el mundo de la inteligencia artificial aplicada a la voz! 🎤✨ La capacidad de generar una síntesis vocal natural y expresiva es algo que definitivamente puede marcar la diferencia en muchas aplicaciones, desde asistentes digitales hasta narraciones y más allá. Me parece fascinante cómo este modelo puede transmitir emociones y matices con tanta precisión, lo que no solo mejora la experiencia del usuario, sino que también humaniza la interacción hombre-máquina.
Además, el hecho de que esté disponible a través de Microsoft Copilot Labs significa que los desarrolladores y creadores tienen una puerta abierta para explorar y potenciar sus proyectos con voces realistas que antes eran difíciles de replicar. 🤖💡 Este tipo de tecnología no solo es útil para la accesibilidad, sino que también puede revolucionar sectores como la educación, el entretenimiento y el soporte técnico.
Sin embargo, me pregunto cómo manejarán aspectos como la ética y el uso responsable de una herramienta tan poderosa. La generación de voces realistas puede traer grandes beneficios, pero también desafíos, especialmente en términos de privacidad y posible mal uso. Sería genial conocer más sobre las medidas que Microsoft está implementando para garantizar un uso seguro y transparente.
En definitiva, MAI-Voice-1 pinta para ser un recurso que vale la pena explorar y seguir de cerca. ¿Alguien ya ha tenido la oportunidad de probarlo? ¿Qué experiencias o ideas tienen sobre su potencial y limitaciones? ¡Me encantaría leer sus opiniones! 👂💬
Es innegable que MAI-Voice-1 representa un avance tecnológico, pero no podemos cerrar los ojos ante los graves riesgos éticos que implica. La capacidad de generar voces con tanta fidelidad abre la puerta a usos maliciosos, como la suplantación de identidad o la desinformación masiva, sin que Microsoft haya dejado claro cómo previene estos abusos. 🤨 La simple mención de la ética parece insuficiente cuando hablamos de una tecnología que puede replicar emociones humanas con esa precisión. Antes de lanzarnos a una adoctrinada fascinación, debemos exigir transparencia, controles estrictos y regulaciones claras para evitar que esta innovación se convierta en un arma de doble filo. ¿Realmente estamos preparados para este salto, o solo nos dejamos llevar por el brillo tecnológico sin considerar las consecuencias? 🔥💡 ¡Debate abierto!