






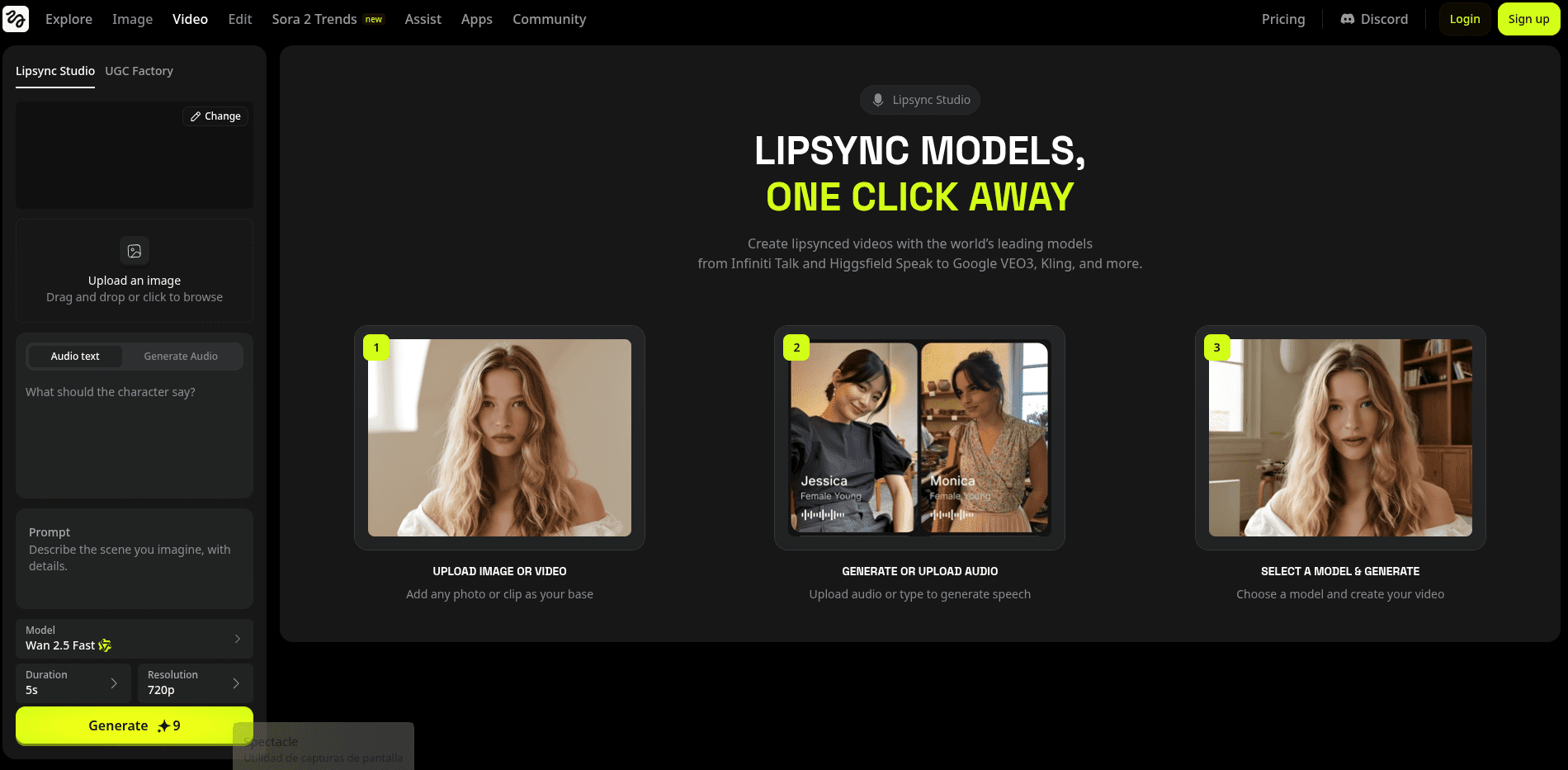
Higgsfield Speak 2.0: Innovación en Síntesis de Voz y Animación Facial
La inteligencia artificial continúa revolucionando la forma en que interactuamos con el contenido digital, y una de sus vertientes más fascinantes es la síntesis de voz y la animación facial sincronizada. Higgsfield Speak 2.0 emerge como una herramienta innovadora que permite a los desarrolladores y creadores hacer que los avatares digitales hablen con movimientos sincronizados de los labios, aportando un mayor realismo y expresividad. Esta tecnología fusiona el procesamiento avanzado del habla con animaciones precisas, facilitando una comunicación digital más natural y atractiva.
En este artículo, exploraremos en profundidad cómo funciona Higgsfield Speak 2.0, su relevancia en el contexto de la síntesis de voz, y las aplicaciones prácticas que pueden transformar sectores como el entretenimiento, la educación y la comunicación virtual.
Síntesis de voz: El fundamento de la comunicación digital
Higgsfield Speak 2.0 revoluciona la manera en que los avatares digitales comunican, gracias a su integración de avances en síntesis de habla y animación facial. Este sistema avanzado logra una sincronización labial increíblemente precisa, lo que resulta en interacciones digitales mucho más naturales y realistas. Para entender cómo se logra este avance, es fundamental profundizar en los fundamentos avanzados en síntesis de habla y animación facial para avatares.
La síntesis de habla, o Text to Speech (TTS), es el proceso mediante el cual el texto es convertido en habla audible. Este proceso comienza con el análisis del texto, donde se identifica y procesa cada palabra para determinar su pronunciación mediante la conversión fonémica. Cada fonema, la unidad básica de sonido en el lenguaje, es luego ensamblado en palabras y oraciones, considerando la entonación, la prosodia, y otros aspectos que hacen al habla natural y comprensible.
Para más información sobre la síntesis de voz, se puede consultar recursos especializados que explican en detalle este proceso revolucionario.
Desafíos y soluciones en la síntesis de voz
Uno de los desafíos más significativos en TTS es lograr una prosodia natural; es decir, los contornos de entonación, el ritmo, y las pausas que hacen que el habla suene auténtica. Además, la naturalidad del habla depende en gran medida de que estos elementos se ajusten de manera precisa al contexto y al significado del texto.
Higgsfield Speak 2.0 aborda estos desafíos utilizando algoritmos avanzados de inteligencia artificial y aprendizaje profundo. Estos algoritmos analizan grandes cantidades de datos de habla real para entender y reproducir los patrones complejos de la prosodia humana. Además, el sistema incorpora técnicas de reconocimiento y generación de voz que permiten ajustar dinámicamente el tono, la velocidad y la emocionalidad del habla, según el contexto del diálogo del avatar.
La integración con animación facial para una experiencia inmersiva
La integración de la síntesis de habla con la animación facial es otro elemento clave que hace de Higgsfield Speak 2.0 una herramienta revolucionaria. Utilizando también IA, el sistema analiza la salida de audio generado y sincroniza los movimientos faciales del avatar, especialmente los movimientos labiales, con el audio de manera precisa.
Esto se logra mediante el modelado de las articulaciones faciales y la predicción de los movimientos necesarios para cada fonema, lo que resulta en una sincronización labial que refleja fielmente el habla generada. Este proceso no solo incluye la sincronización de los movimientos labiales, sino también la generación de expresiones faciales completas que corresponden a las emociones y los matices del habla, enriqueciendo así la experiencia de interacción con el avatar.
El resultado es una comunicación digital increíblemente realista y una mayor inmersión del usuario, transformando la forma en que interactuamos con los avatares digitales. Para profundizar en esta técnica, se puede revisar el desarrollo histórico y técnico de la animación facial.
¿ Quieres DESTACAR este recurso, herramienta o plataforma sobre Inteligencia Artificial? ¿ Te gustaría estar presente en nuestro directorio ? HAZ CLICK AQUÍ
https://directorio.agentesinteligentes.es/contacto/
Aplicaciones y ventajas de Higgsfield Speak 2.0
Este avanzado sistema tiene un impacto notable en diversos sectores:
- Entretenimiento: videojuegos y animaciones ganan en realismo y expresividad a través de avatares que hablan con naturalidad.
- Educación: crea experiencias de aprendizaje personalizadas con tutores virtuales capaces de transmitir información de manera clara y emocionalmente adecuada.
- Comunicación virtual: mejora la accesibilidad y la interacción en plataformas digitales, facilitando diálogos más efectivos y cercanos.
Para desarrolladores y empresas, la incorporación de Higgsfield Speak 2.0 representa ventajas significativas en la experiencia de usuario, permitiendo contenido digital más envolvente y personalizado.
Conclusiones
Higgsfield Speak 2.0 representa una avanzada solución tecnológica que une de manera efectiva la síntesis de habla y la animación facial sincronizada para crear avatares digitales que hablan con realismo y naturalidad. Su integración del procesamiento avanzado de texto a voz, junto con algoritmos que gestionan la sincronización labial y el movimiento facial, abre nuevas posibilidades para campos tales como videojuegos, educación virtual, interfaces interactivas y comunicación digital.
Se recomienda implementar Higgsfield Speak 2.0 en proyectos donde la expresividad y claridad vocal sean prioritarios, asegurando una correcta optimización según la plataforma destino para mantener la calidad en tiempo real. Además, se sugiere complementar esta herramienta con tecnologías de reconocimiento de emociones para enriquecer aún más la interacción emocional con los usuarios.
En definitiva, Higgsfield Speak 2.0 es una herramienta clave para cualquier profesional del sector IA que busque innovar en la creación de experiencias digitales realistas y comunicativas.
– Web Oficial de Higgsfield Speak 2.0 = https://higgsfield.ai/create/speech.
2 respuestas
🚀 ¡Wow! Higgsfield Speak 2.0 me parece una herramienta fascinante y super útil para quienes buscamos darle vida a nuestros avatares digitales. La capacidad de sincronizar perfectamente los movimientos labiales con el texto es todo un avance que mejora la expresividad y naturalidad en presentaciones virtuales. 🌟 Además, que soporte múltiples idiomas abre un universo de posibilidades para creadores y educadores globales. Me encanta que sea tan versátil, perfecta para desarrollar contenidos más dinámicos y atractivos. No es solo tecnología, sino una oportunidad para conectar con nuestra audiencia de forma más emocional y auténtica, algo imprescindible hoy en día. Sin embargo, me pregunto cómo se maneja la personalización de movimientos más sutiles o emociones faciales complejas, ¿será posible ajustar esos detalles para un toque aún más realista? 🤔 En cualquier caso, ¡gran innovación que invita a experimentar y explorar nuevos formatos audiovisuales! ¿Alguien ya la ha probado? Me encantaría saber qué tal les ha funcionado y en qué proyectos la están usando. 💬 #TecnologíaQueInspira #AvataresDigitales #InnovaciónAI
🚨 Tito, comprendo tu entusiasmo, pero creo que hay que ser realistas con Higgsfield Speak 2.0. La promesa de sincronización labial perfecta y soporte para múltiples idiomas suena genial, pero no se menciona en el artículo ningún detalle técnico sobre personalización avanzada de emociones o movimientos faciales sutiles. La IA puede imitar patrones básicos, pero una verdadera expresividad emocional profunda y natural aún está lejos de alcanzarse con estos sistemas automatizados. Además, la precisión en tiempos reales podría verse afectada por limitaciones de hardware o conexión, algo que el artículo pasa por alto. No podemos dejarnos llevar solo por el marketing; hace falta más transparencia sobre las capacidades reales y las limitaciones de esta tecnología antes de anunciarla como una revolución absoluta. ¿Realmente cumple con las expectativas de proyectos profesionales exigentes? 🤔