






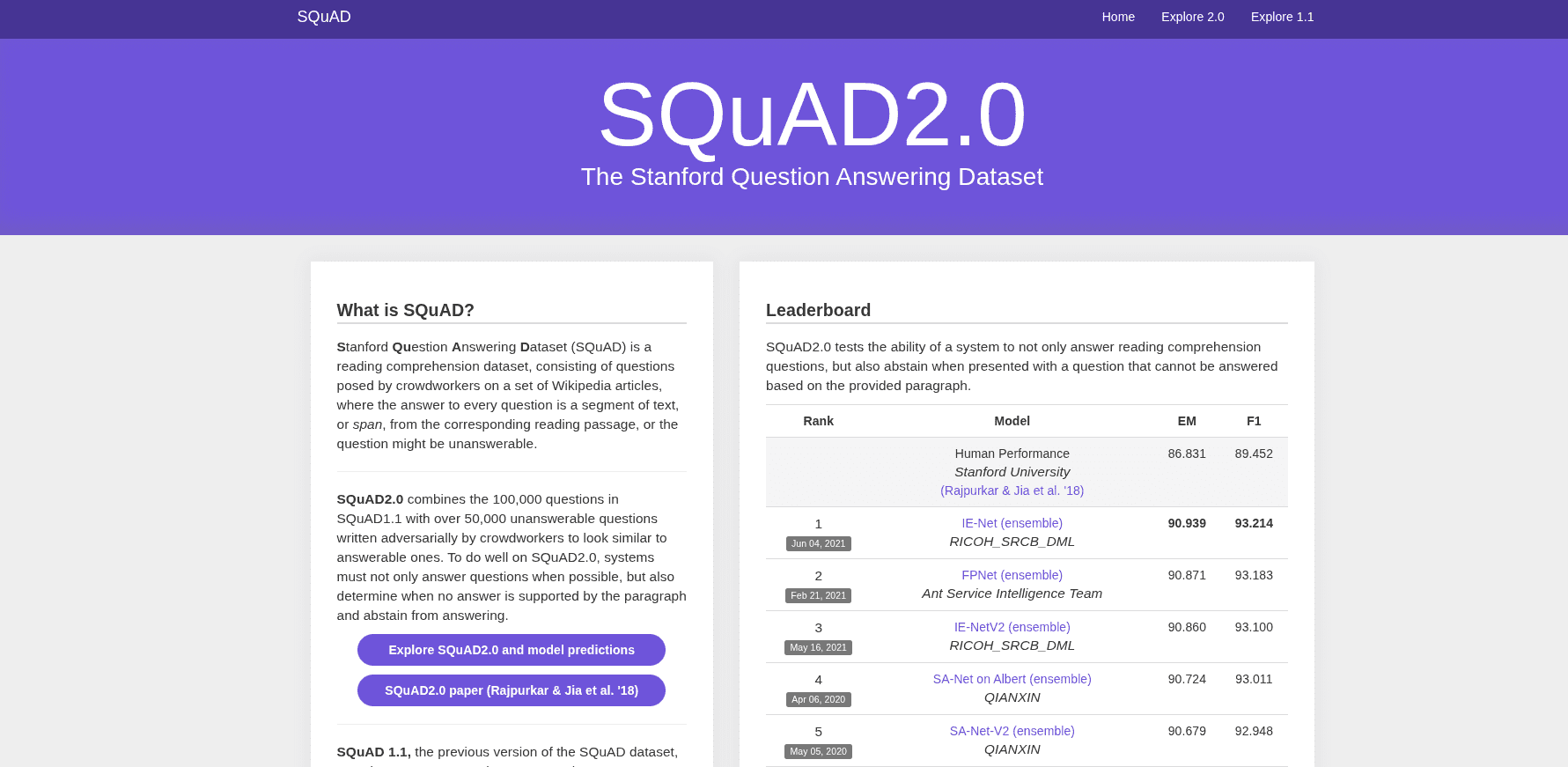
En la evolución de la inteligencia artificial, especialmente en el área de procesamiento del lenguaje natural (PLN), el Stanford Question Answering Dataset (SQuAD) ha emergido como un recurso fundamental para medir y mejorar la capacidad de los modelos para entender y responder preguntas de manera precisa. Este dataset es una herramienta de evaluación que contiene preguntas formuladas en lenguaje natural basadas en textos extraídos de artículos de Wikipedia, desafiando a los sistemas a identificar y generar respuestas correctas dentro del contexto proporcionado.
En esta era donde los modelos de lenguaje desempeñan un papel crucial en aplicaciones desde asistentes virtuales hasta análisis de contenido, comprender cómo funciona SQuAD y su contribución al desarrollo de tecnologías de PLN es vital para investigadores, desarrolladores y entusiastas del campo. El presente artículo explorará en detalle la estructura, importancia y aplicaciones del Stanford Question Answering Dataset, ofreciendo un análisis técnico experto que facilite su aprovechamiento en proyectos de inteligencia artificial.
El papel del Stanford Question Answering Dataset en el procesamiento del lenguaje natural
El Stanford Question Answering Dataset (SQuAD) ha emergido como uno de los recursos más relevantes en la revolución del procesamiento del lenguaje natural (PLN), particularmente en lo que respecta a los sistemas de preguntas y respuestas (QA). Esta innovadora herramienta, compuesta por un amplio conjunto de preguntas planteadas por humanos y basadas en pasajes extractados de artículos de Wikipedia, destaca por su peculiar estructura y los múltiples retos que presenta para la comprensión lectora automatizada.
La esencia de SQuAD reside en su capacidad para facilitar la comparación objetiva y rigurosa entre modelos de QA, poniendo a prueba no solo su precisión en la identificación de respuestas correctas, sino también su habilidad para manejar las sutilezas y complejidades del lenguaje natural. En este sentido, SQuAD se ha consolidado como una herramienta indispensable para el avance tecnológico en el campo del PLN, dado que obliga a investigadores y desarrolladores a enfrentarse a desafíos que van desde el entendimiento de contextos variados hasta la interpretación de preguntas con estructuras complejas.
Características clave del Stanford Question Answering Dataset
El núcleo de SQuAD está diseñado para abarcar una diversidad de preguntas, que van desde aquellas cuyas respuestas pueden ser extractadas directamente de los textos, hasta interrogantes que requieren de una comprensión más profunda y razonamiento deductivo por parte de los sistemas QA. Esta característica ha propiciado que SQuAD no solo sea un mecanismo para evaluar la capacidad de extracción de información, sino también un criterio para medir cuán efectivamente pueden los modelos entender el significado integral de los textos, reconociendo relaciones causales, implicaciones y referencias dentro de los mismos.
El formato de SQuAD, basado en pares pregunta-respuesta vinculados a pasajes específicos de Wikipedia, provee una plataforma idónea para el desarrollo de sistemas de QA que aspiren a interactuar de manera más natural e intuitiva con el usuario final. La exigencia de que las respuestas han de ser localizadas dentro de los textos promueve una aproximación al PLN que va más allá de la simple búsqueda de palabras clave, inclinándose hacia la interpretación y comprensión textual en niveles de sofisticación mayor.
Impacto de SQuAD en el desarrollo de tecnologías inteligentes
Frente a la creciente demanda de interfaces conversacionales más eficientes, inteligentes y humanizadas, el Stanford Question Answering Dataset se posiciona como un referente crítico en la investigación y desarrollo de tecnologías PLN avanzadas. Al proporcionar un vasto corpus de datos con el cual entrenar y evaluar modelos de IA, SQuAD no solo facilita la mejora continua de los sistemas de QA existentes, sino que también impulsa la innovación hacia nuevas fronteras en el entendimiento automático del lenguaje natural, marcando un hito en la evolución constante de la inteligencia artificial.
Conclusiones
El Stanford Question Answering Dataset representa un recurso indispensable para la comunidad que desarrolla y evalúa sistemas de procesamiento del lenguaje natural. Su estructura basada en preguntas derivadas de textos reales extraídos de Wikipedia permite simular escenarios que demandan un alto nivel de comprensión, contextualización y precisión en la generación de respuestas automatizadas.
Desde un punto de vista técnico, su uso es fundamental para validar modelos en términos de exactitud y robustez, fomentando la implementación de arquitecturas avanzadas como redes neuronales profundas y transformers, que han demostrado gran capacidad para capturar relaciones semánticas complejas. Su contribución ha facilitado el avance de sistemas más confiables y eficientes, adaptables a diversos dominios y aplicaciones.
Por ello, se recomienda a profesionales e investigadores en inteligencia artificial integrar SQuAD como benchmark estándar en sus procesos de desarrollo y validación, aprovechando su amplia adopción y recursos disponibles. Asimismo, deben considerarse sus limitaciones, complementándolo con datasets adicionales para cubrir aspectos multimodales o dominios especializados, y mantenerse actualizados con las nuevas versiones y variantes que surgen para enfrentar retos cada vez más sofisticados en el campo del PLN.
– Web Oficial = https://rajpurkar.github.io/SQuAD-explorer/